데이터 전처리(1): https://insighted-h.tistory.com/16
[Machine Learning] 데이터 전처리(1) - 결측치 처리(1)
데이터 분석을 하기 위해서 데이터의 전처리는 필수적이다. 데이터들을 수집해서 나온 가공되지 않은 데이터는 분석을 바로 할 수가 없는 상태이다. (결측치의 존재, 이상치의 존재, 여러 데이
insighted-h.tistory.com
이전 포스팅에서는 결측치를 다루는 방법에 대해서 알아보았다. 현실 데이터에서는 우리가 예측하고자 하는 클래스가 불균형할 때가 흔하다. 대표적인 예로 다음과 같은 상황이 있다.
- 신용카드 사기 탐지: 신용카드 거래에서 사기 거래는 정상적인 거래에 비해 매우 드문 케이스
- 스팸 메일 분류하기: 스팸 메일 vs 정상 메일
- 불량품 판단하기
이렇게 예측하고자 하는 클래스 간에 불균형이 있을 경우, 모델의 학습은 정상적으로 진행되지 않는다. 다수를 차지하는 클래스에 모델이 편향되어 학습하게 되어 결과적으로 모델은 안 좋은 예측을 만들어낸다.
Imbalanced class를 처리하는 방법에는 어떤 방법들이 있을까?
아래와 같은 방법들을 활용하여 imbalanced class 문제를 다룰 수 있다.
1. 평가 기준 바꾸기
일반적으로 분류 문제의 평가 방법으로 정확도(Accuracy)를 많이 사용한다. 그러나, imbalanced class일 경우에는 정확도는 더 이상 좋은 평가 방법이 아니다.
아래와 같은 경우를 생각해보자.
신용카드 사기 거래 데이터: 0(정상 거래) 9900건, 1(사기 거래) 100건
만약에 위의 데이터에 대해 모델이 모든 거래를 0(정상 거래)으로 예측했다고 하자.
그렇다면 명백하게 예측을 제대로 못하는 엉터리 모델이라고 할 수 있다.
그러나 정확도로 평가한다면 매우 좋은 모델처럼 보이게 된다. 정확도는 9900/10000 * 100 = 99%가 나오기 때문이다.
그러나 다음과 같이 오차 행렬(confusion matrix)표를 그려본다면 모델에 대해 정확한 평가를 내릴 수 있다.
| True Values | |||
| Predicted Values | 0 | 1 | |
| 0 | 9900 | 100 | |
| 1 | 0 | 0 | |
imbalanced class 문제일 때에는 평가 기준을 알맞게 바꿔줘야 한다.
수치화시키고 싶다면 f1-score나 Logloss를 사용하기도 한다.
평가 지표에 대한 자세한 설명은 아래 포스팅을 참고해보면 좋을 것 같다.
[Machine Learning] 분류 측정 지표
분류는 머신러닝의 대표적인 기법 중 하나이다. 정말 다양한 분류 알고리즘이 있고, 아직 데이터분석을 시작한 지 얼마 안 된 초보자 입장이지만, 현재까지 웬만한 문제들은 분류 알고리즘 기반
insighted-h.tistory.com
2. Resampling (Under-sampling /Over-sampling)
imbalanced class를 해결하기 위해 두 데이터의 비율을 맞춰주는 것이다.

Under-sampling은 다수 클래스에서 다시 샘플링하여 소수 클래스와의 비율을 맞춰준다.
Over-sampling은 이와 반대로 소수 클래스를 복제하여 다수 클래스와 비율을 비슷하게 맞춰준다.
Resampling 기법은 비교적 쉽게 imbalanced class 문제를 해결할 수 있다는 장점이 있지만, 단점 또한 명확하다.
Under-sampling은 다수의 데이터를 제거하기 때문에 정보의 손실이 크고, 예측 결과가 안 좋을 수 있다.
Over-sampling은 소수 클래스를 복제해서 비율을 맞추기 때문에 Over-fitting이 발생할 가능성이 크다.
3. Cluster Centroids
Cluster Centroids 기법은 대표적인 Under-sampling 기법 중 하나이다.
Cluster Centroids 기법은 다수 클래스에서 Random으로 데이터를 추출하지 않고 K-means 알고리즘에 기반해서
Under-sampling한다.
4. SMOTE(Synthetic Minority Over-sampling Technique)
SMOTE 기법은 대표적인 Over-sampling 기법 중 하나이다.
SMOTE는 데이터를 단순 복사해서 수를 늘리는 것이 아니라 최근접 알고리즘 (k-NN 알고리즘)에 기반해서
합성 데이터를 만들어낸다.
복제가 아닌 합성 데이터로 Over-sampling하기 때문에 기존 방식에 비해 Over-fitting이 일어날 가능성이 더 적다.
5. One-class learning
알고리즘 기법으로 One-class learning을 사용할 수 있다. One-class learning은 학습을 통하여 다수 그룹의 경계선을 정하고 벗어나면 소수 그룹으로 분류하는 알고리즘이다. 주로 이상 탐지 등에 사용하는 알고리즘이다.
SVDD 알고리즘을 적용해서 다수 클래스를 최대화시키는 hyperspace를 찾는다.
One-class learning은 다수 클래스와 나머지로 나눈다.
6. Cost-sensitive learning
또 다른 알고리즘 기법으로 Cost-sensitive learning이 있다. Cost-sensitive learning은 misclassification cost를 최소화하는 알고리즘인데, 소수 클래스를 잘못 분류할 때 큰 페널티를 주는 알고리즘이다.
+: positive class (small class)
-: negative class (large class)
C(+,-): Cost of false negative (positive -> negative)
C(-,+): Cost of false positive (negative -> positive)
Set C(+,-) > C(-,+), minimize the expected cost
7. Class weights
Class 간의 불균형을 조절하기 위해 class weights를 다르게 설정할 수도 있다. 소수 클래스에 큰 가중치를 부여하는 방법이다. 얼핏 보기에는 Cost-sensitive learning과 비슷하게 보일 수 있지만 Cost-sensitive learning은 코스트에 초점을 맞춰서 페널티에 집중하는 반면, class weights는 클래스 간에 가중치를 다르게 줘서 중요도를 다르게 설정한다.
How to Improve Class Imbalance using Class Weights in Machine Learning?
Deal with imbalanced classes in machine learning by improving the class imbalance using Python and improve your model using class weights.
www.analyticsvidhya.com
위의 블로그에 따르면 아래와 같이 클래스 가중치를 계산할 수 있다고 한다.
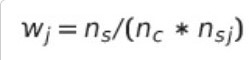
ns: 샘플 수 / nc: 클래스 수
예를 들어 위의 케이스는 아래와 같이 클래스 가중치를 계산할 수 있다.
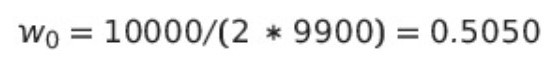
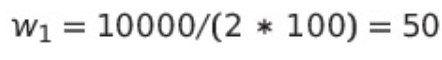
참고자료
[1] "Resampling strategies for imbalanced datasets", Kaggle, Rafael Alencar
https://www.kaggle.com/code/rafjaa/resampling-strategies-for-imbalanced-datasets/notebook#t10
[2] "How to improve class imbalance using class weights in machine learning?", Analytics Vidya, Kamaldeep Singh
'Data Science > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 데이터 전처리(2) - Imbalanced class(2) (0) | 2023.08.19 |
|---|---|
| [Machine Learning] 데이터 전처리(1) - 결측치 처리(2) (0) | 2023.06.26 |
| [Machine Learning] 데이터 전처리(1) - 결측치 처리(1) (0) | 2023.06.22 |
| [Machine Learning] 평가 지표 - 분류(Classification) (0) | 2023.02.07 |
| [Machine Learning] 손실 함수 (loss function) (0) | 2023.01.31 |



