데이터 분석 전처리에서 가장 중요한 작업 중 하나는 바로 결측치를 처리하는 일이다. 데이터셋에는 결측치가 포함되어 있는 경우가 많은데, 판다스는 결측치 처리를 위해 여러 가지 편리한 함수들을 제공하고 있다.
1. NaN
판다스에서는 결측치를 다음과 같이 NaN으로 표시한다.
df = pd.DataFrame(
np.random.randn(5, 3),
index=["a", "c", "e", "f", "h"],
columns=["one", "two", "three"],
)
df["four"] = "bar"
df["five"] = df["one"] > 0
df
=>
one two three four five
a -0.405825 1.266212 -0.629770 bar False
c 0.897918 -1.657066 -0.660260 bar True
e 0.189848 0.886901 0.666665 bar True
f 0.899519 -0.895818 0.283082 bar True
h 0.433419 -0.667241 1.188534 bar Truedf2 = df.reindex(["a", "b", "c", "d", "e", "f", "g", "h"])
df2
=>
one two three four five
a 0.469112 -0.282863 -1.509059 bar True
b NaN NaN NaN NaN NaN
c -1.135632 1.212112 -0.173215 bar False
d NaN NaN NaN NaN NaN
e 0.119209 -1.044236 -0.861849 bar True
f -2.104569 -0.494929 1.071804 bar False
g NaN NaN NaN NaN NaN
h 0.721555 -0.706771 -1.039575 bar True파이썬에서 None값으로 입력할 경우, 결측치 NaN으로 처리함을 확인할 수 있다.
df2.loc['a','one'] = None
df2
=>
one two three four five
a NaN 1.408042 0.391331 bar True
b NaN NaN NaN NaN NaN
c 0.108553 1.299275 -0.958130 bar True
d NaN NaN NaN NaN NaN
e -0.814288 -0.306688 1.815885 bar False
f -0.299036 0.773543 2.214685 bar False
g NaN NaN NaN NaN NaN
h -1.302370 1.689859 -0.650966 bar False
# df2의 첫번째 원소가 NaN으로 바뀌었다.
2. isna(), isnull()
판다스의 데이터프레임은 isna() 메서드로 결측치를 확인할 수 있다. 단 한 줄의 코드로 데이터의 결측치 유무를 확인할 수 있기 때문에 매우 유용하다.
df2.isna()
=>
one two three four five
a True False False False False
b True True True True True
c False False False False False
d True True True True True
e False False False False False
f False False False False False
g True True True True True
h False False False False False
# df2.isnull()도 마찬가지로 같은 결과를 보여준다.아래와 같이 결측치에 대한 그래프를 그려서 시각화도 가능하다.
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(12,6))
sns.barplot(x=df2.columns, y=df2.isnull().sum(), palette='YlOrRd')
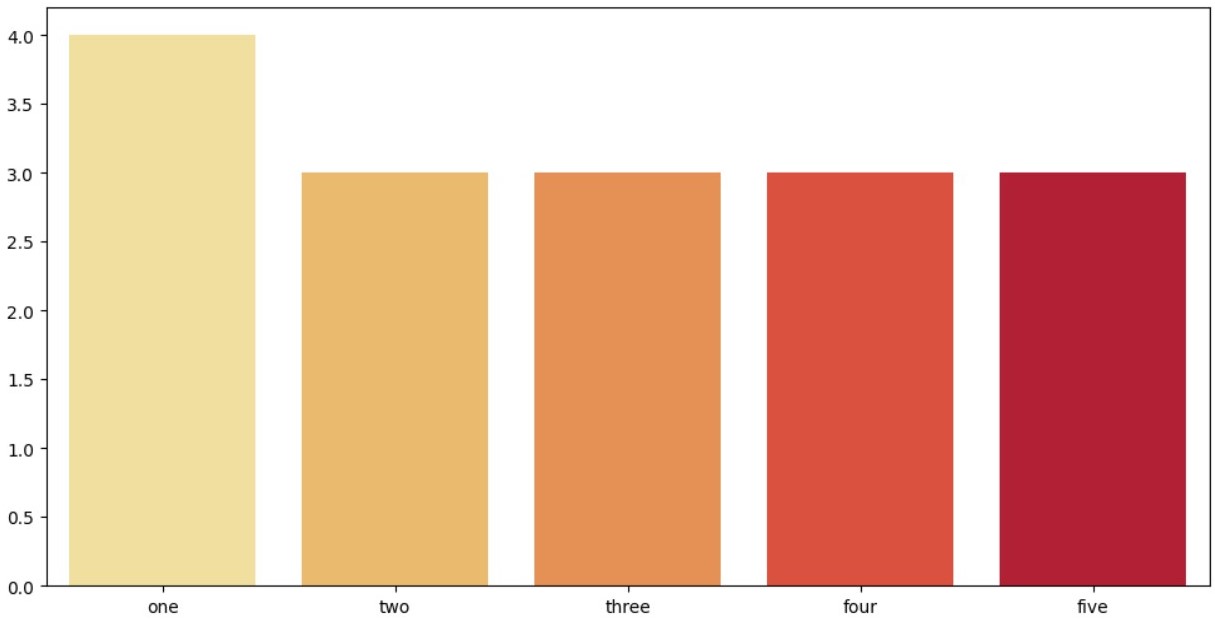
3. fillna()
fillna() 메서드로 결측치를 채워넣을 수 있다.
df2.fillna(0)
=>
one two three four five
a 0.000000 1.408042 0.391331 bar True
b 0.000000 0.000000 0.000000 0 0
c 0.108553 1.299275 -0.958130 bar True
d 0.000000 0.000000 0.000000 0 0
e -0.814288 -0.306688 1.815885 bar False
f -0.299036 0.773543 2.214685 bar False
g 0.000000 0.000000 0.000000 0 0
h -1.302370 1.689859 -0.650966 bar False
# 모든 결측치를 0으로 채워넣었다.또는 mean() 메서드로 각 컬럼에 대한 평균값으로 대체되는 것을 볼 수 있다.
df2.fillna(df2.mean())
=>
one two three four five
a -0.576785 1.408042 0.391331 bar True
b -0.576785 0.972806 0.562561 NaN 0.4
c 0.108553 1.299275 -0.958130 bar True
d -0.576785 0.972806 0.562561 NaN 0.4
e -0.814288 -0.306688 1.815885 bar False
f -0.299036 0.773543 2.214685 bar False
g -0.576785 0.972806 0.562561 NaN 0.4
h -1.302370 1.689859 -0.650966 bar False
df2.fillna(df2.mean()["two":"three"])
=>
one two three four five
a NaN 1.408042 0.391331 bar True
b NaN 0.972806 0.562561 NaN NaN
c 0.108553 1.299275 -0.958130 bar True
d NaN 0.972806 0.562561 NaN NaN
e -0.814288 -0.306688 1.815885 bar False
f -0.299036 0.773543 2.214685 bar False
g NaN 0.972806 0.562561 NaN NaN
h -1.302370 1.689859 -0.650966 bar False
# 아래 예제는 두 번째와 세 번째 컬럼만 채워넣었다.3-1. replace()
replace() 메서드로 좀 더 자유롭게 결측치를 처리할 수 있다.
df2.replace({"one":np.NaN,"two":np.NaN}, 100)
=>
one two three four five
a 100.000000 1.408042 0.391331 bar True
b 100.000000 100.000000 NaN NaN NaN
c 0.108553 1.299275 -0.958130 bar True
d 100.000000 100.000000 NaN NaN NaN
e -0.814288 -0.306688 1.815885 bar False
f -0.299036 0.773543 2.214685 bar False
g 100.000000 100.000000 NaN NaN NaN
h -1.302370 1.689859 -0.650966 bar False
# 첫 번째와 두 번째 컬럼의 결측치를 모두 100으로 바꿨다.
4. dropna()
dropna() 메서드는 결측치가 포함된 행 또는 열을 없애는 메서드이다. 파라미터 axis 값으로 행 방향 또는 열 방향을 설정할 수 있다.
df2.dropna(axis=0)
=>
one two three four five
c 0.108553 1.299275 -0.958130 bar True
e -0.814288 -0.306688 1.815885 bar False
f -0.299036 0.773543 2.214685 bar False
h -1.302370 1.689859 -0.650966 bar False
df2.dropna(axis=1)
=>
a
b
c
d
e
f
g
h참고자료
[1] "Working with missing data", Pandas
https://pandas.pydata.org/docs/user_guide/missing_data.html
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 판다스 데이터프레임 합치기 (merge, concatenate) (0) | 2023.02.07 |
|---|---|
| [Pandas] 판다스 인덱싱 (loc, iloc) (0) | 2023.02.04 |
| [Pandas] 판다스 기본 함수들 (1) | 2023.02.03 |
| [Pandas] 판다스(Pandas)와 데이터 구조 (1) | 2023.01.31 |



