데이터 분석을 할 때 항상 빠지지 않는 삼대장 패키지가 있다.
바로 NumPy, Pandas, Matplotlib이다.
그 중 판다스는 데이터 조작 및 분석 작업을 매우 편리하게 만들어주는 패키지이다. 판다스의 공식문서는 아래 링크를 통해 들어갈 수 있다. User Guide와 API 모두 상당히 친절하고 자세하다.
판다스 공식문서: https://pandas.pydata.org/
pandas - Python Data Analysis Library
pandas pandas is a fast, powerful, flexible and easy to use open source data analysis and manipulation tool, built on top of the Python programming language. Install pandas now!
pandas.pydata.org
나 또한 데이터 분석 작업을 시작할 때, 언제나 사용하고 있는 패키지이다. 그러나, 판다스에 대해서 제대로 배워본 적이 없기에 막힐 때마다 구글링을 하고, 조금씩 기초체력이 약하다는 느낌을 받았다. 그래서 제대로 한 번 공부해봐야겠다는 생각이 들었고, 이번 기회에 판다스를 마스터한다는 느낌으로 철저히 배워보겠다.
판다스 불러오기 및 기본 환경
판다스는 일반적으로 다음과 같이 불러온다. 보통 약자로 pandas의 약자로 pd를 사용한다.
import pandas as pd만약 판다스 라이브러리가 작업 환경에 없다면, 아래 코드로 판다스 라이브러리를 설치하면 된다.
pip install pandas판다스의 버전을 확인하고 싶다면 다음 코드로 확인해볼 수 있다.
pd.__version__
=> 1.3.5현재 나는 1.3.5 버전을 쓰고 있는 것을 볼 수 있다.
판다스의 데이터 구조
판다스에서는 판다스만의 아래와 같은 두 가지의 새로운 데이터 구조를 정의한다.
- Series
- Dataframe
1. Series
첫 번째는 Series이다. Series는 넘파이의 ndarray와 매우 유사하게 동작한다. Series는 레이블 되어있는 1차원 배열 형태의 구조이고, 어떠한 데이터 타입(integers, floats, strings, ...)도 Series의 요소가 될 수 있다. Series의 요소는 인덱스로 부를 수 있다.
Series를 생성하는 방법은 다음과 같다.
a = pd.Series(data, index=index)data는 파이썬의 list, dictionary, ndarray 또는 스칼라 값 등 다양한 형태를 가질 수 있다. 데이터 타입이 ndarray인 데이터에 인덱스를 부여할 경우, 인덱스의 크기는 data의 크기와 같아야 한다. Series 생성 시 인덱스는 생략 가능하며, 인덱스를 생략할 시, 0, ..., len(data)-1의 숫자가 자동으로 부여된다.
아래는 Series를 생성한 예시이다.
a = pd.Series([1,2,3,4,5], index=['a','b','c','d','e'])
a
=>
a 1
b 2
c 3
d 4
e 5
dtype: float64type()으로 확인해보면 결과는 다음과 같다.
type(a)
=> pandas.core.series.Series위의 출력 결과에서 왼쪽에 인덱스가, 오른쪽에 값이 나오는 것을 확인할 수 있다.
생성된 Series의 인덱스와 값들은 아래 코드로 확인할 수 있다.
a.index
=> Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
a.values
=> array([1, 2, 3, 4, 5])데이터가 딕셔너리라면 저절로 인덱스가 부여된다.
d = {"b": 1, "a": 0, "c": 2}
pd.Series(d)
=>
b 1
a 0
c 2
dtype: int64인덱스의 크기가 더 크다면 NaN 값으로 새로운 요소가 생긴다.
pd.Series(d, index=["b", "c", "d", "a"])
=>
b 1.0
c 2.0
d NaN
a 0.0
dtype: float64Series는 넘파이의 ndarray처럼 작동한다. 인덱싱 뿐만 아니라 연산 또한 가능하다.
a[1:3]
=>
b 2
c 3
dtype: int64
a[a > a.median()]
=>
d 4
e 5
dtype: int64
np.exp(a)
=>
a 2.718282
b 7.389056
c 20.085537
d 54.598150
e 148.413159
dtype: float64또한 딕셔너리처럼 사용도 가능하다.
a["a"]
=>
1
"e" in a
=>
True
"f" in a
=>
False이외에도 다양한 기능들이 있지만 후에 다시 공부해서 정리해보겠다.
2. Dataframe
Dataframe은 2차원 형태의 데이터 구조이다. 행과 열로 구성되어 있으며, 엑셀의 스프레드시트와 비슷하다. 실제 데이터분석 시에 많은 데이터 파일들이 csv나 xlsx등의 확장자를 가지고 있는데, Dataframe 데이터 구조를 통해 바로 읽어들일 수 있기 때문에 매우 유용한 데이터 구조라고 할 수 있다.
Dataframe의 생성은 아래와 같이 할 수 있다.
d = {
"one": pd.Series([1.0, 2.0, 3.0], index=["a", "b", "c"]),
"two": pd.Series([1.0, 2.0, 3.0, 4.0], index=["a", "b", "c", "d"]),
}
df = pd.DataFrame(d)
df
=>
one two
a 1.0 1.0
b 2.0 2.0
c 3.0 3.0
d NaN 4.0행과 열은 각각 index와 columns 속성으로 확인할 수 있다.
df.index
=>
Index(['a', 'b', 'c', 'd'], dtype='object')
df.columns
=>
Index(['one', 'two'], dtype='object')index를 지정해주지 않으면 아래처럼 숫자가 0부터 자동으로 부여된다.
d = {"one": [1.0, 2.0, 3.0, 4.0], "two": [4.0, 3.0, 2.0, 1.0]}
pd.DataFrame(d)
=>
one two
0 1.0 4.0
1 2.0 3.0
2 3.0 2.0
3 4.0 1.0Dataframe은 각 열을 선택해서 마치 Series처럼 연산이 가능하다.
df["one"]
=>
a 1.0
b 2.0
c 3.0
d NaN
df["three"] = df["one"] * df["two"]
df["flag"] = df["one"] > 2
df
=>
one two three flag
a 1.0 1.0 1.0 False
b 2.0 2.0 4.0 False
c 3.0 3.0 9.0 True
d NaN 4.0 NaN FalseDataframe은 인덱싱 결과에 따라 Series 또는 Dataframe을 반환한다.
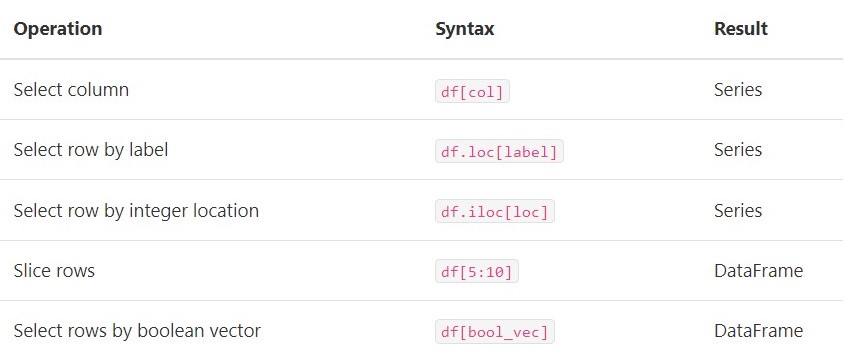
Dataframe 인덱싱에 대한 자세한 내용은 후에 더 공부해서 정리해보겠다.
참고자료
[1] "Intro to data structures", Pandas, https://pandas.pydata.org/docs/user_guide/dsintro.html
'Python > Pandas' 카테고리의 다른 글
| [Pandas] 판다스 결측치 처리 (2) | 2023.06.19 |
|---|---|
| [Pandas] 판다스 데이터프레임 합치기 (merge, concatenate) (0) | 2023.02.07 |
| [Pandas] 판다스 인덱싱 (loc, iloc) (0) | 2023.02.04 |
| [Pandas] 판다스 기본 함수들 (1) | 2023.02.03 |



