머신러닝 알고리즘 중에서 분류는 직관적이면서 가장 기초적인 알고리즘이다.
분류로 해결할 수 있는 대표적인 문제들을 예로 들자면,
- 타이타닉 데이터셋으로부터 생존자 예측하기 (생존 or 사망)
- 고객들의 금융 데이터셋으로부터 대출 가능 여부 예측하기 (가능 or 불가능)
- 1~10까지의 숫자 이미지가 들어있는 MNIST 데이터셋으로부터 해당 숫자가 몇인지 분류하기
이처럼 데이터셋으로부터 특징들을 파악하여 모델을 학습시키고, 분류 결과를 도출해낸다.
분류 알고리즘은 어떤 것들이 있을까? 아래는 머신러닝에서 주로 사용하는 알고리즘들이다.
1. Logistic Regression (로지스틱 회귀모형)

첫 번째로 자주 사용하는 분류 모델은 Logistic Regression이다. 이름에 회귀라는 말이 들어가있어서 처음에 엥? 회귀인데 분류에 사용되는 모형이라고? 생각이 들지만, 결과값이 '예', '아니오'처럼 두 가지밖에 없는 이진 분류기에 사용 가능하다. 함숫값은 어떤 사건이 발생될 확률로 0에서 1 사이의 값이 된다. 경계값 0.5를 기준으로 0.5보다 크다면 양성 클래스, 0.5보다 작다면 음성 클래스로 분류한다.
예를 들어 타이타닉 데이터셋에서 Logistic Regression 모형으로 훈련시키고, 첫 번째 고객에 대한 값이 0.7이 나왔다면, 모형이 그 사람의 생존 확률을 0.7로 예측했다는 얘기가 되고, 모델은 생존으로 예측할 것이다.
2. Stochastic Gradient Descent (확률적 경사 하강법)
두 번째는 확률적 경사 하강법 알고리즘을 사용한 분류 알고리즘이다. 경사 하강법은 손실 함수를 설정하고 이를 최소화시켜나가는 과정이다. 다음과 같은 식을 배경으로 그레이디언트를 0에 가깝게 줄여나가서 최적해를 찾게 된다.


그러나, 기울기가 0인 곳에서 알고리즘이 종료되기 때문에 자칫 지역 최솟값에 갇힐 수 있다. 지역 최솟값에 갇히는 것을 방지하고, 학습 속도(학습 반복 횟수) 조절을 위해서 학습률을 곱해서 해결한다. 각 반복마다 무작위로 샘플 데이터셋을 선택해서 경사 하강법을 진행하기 때문에 학습 속도가 빠르지만 무작위성으로 인해 불안정하다.

3. K-nearest neighbor (k-최근접 이웃)
또 다른 알고리즘은 knn 알고리즘이다. k개로 분류 클래스 개수를 알려주고, 데이터셋을 학습시킨뒤 테스트 데이터에 대해 트레이닝 포인트들과의 거리를 계산해서 분류하는 알고리즘이다. 아래는 파랑과 빨강, 두 가지로 분류하는 문제에서 초록색 데이터를 분류하는 그림을 나타낸 것이다.

이상치에 대해 민감하지 않고, 데이터셋이 클 경우 효과적이다.
4. Decision Tree (의사결정나무)
의사결정나무는 나무에서 가지가 뻗듯이 특성들에 따라 분류를 진행하는 알고리즘이다. 아래와 같은 모습으로 의사결정나무를 완성시키며, 데이터셋을 분류시킨다.

의사결정나무는 나무에 적절한 제약을 걸어놓지 않으면 마지막 노드의 샘플이 하나가 남을 때까지 진행할 수 있기 때문에 과대적합의 가능성이 높다.
5. Support Vector Machine (서포트 벡터 머신)
서포트 벡터 머신은 트레이닝 데이터셋들을 최대한의 공백이 남도록 나누는 알고리즘이다. 그래서 훈련 후 테스트 데이터에 대해서 경계선을 기준으로 분류하게 된다.

경계선은 간단히 선형이 될 수도 있지만, 다항함수의 형태가 될 수도, 방사형 기저 함수 등등 여러 가지가 가능하다.
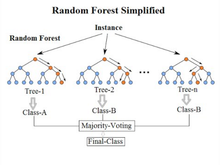
6. Random Forest (랜덤포레스트)
마지막으로 랜덤포레스트는 다수의 결정 트리들을 학습하여 최적의 결과를 만들어내는 알고리즘이다. 일반적으로 여러 개의 결정 트리를 학습하기 때문에 과대적합이 덜하고 정확성이 좋다. 때문에 대회에서도 자주 사용되고 있는 알고리즘이다.
참고자료
[1] Antony Christopher, "K-Nearest Neighbor", Medium, https://medium.com/swlh/k-nearest-neighbor-ca2593d7a3c4
[2] Rohit Garg, "7 Types of Classification Algorithms", Analytics India Magazine, https://analyticsindiamag.com/7-types-classification-algorithms/
'Data Science > Machine Learning' 카테고리의 다른 글
| [Machine Learning] 데이터 전처리(1) - 결측치 처리(1) (0) | 2023.06.22 |
|---|---|
| [Machine Learning] 평가 지표 - 분류(Classification) (0) | 2023.02.07 |
| [Machine Learning] 손실 함수 (loss function) (0) | 2023.01.31 |
| [Machine Learning] 지도 학습 vs 비지도 학습 vs 강화 학습 (0) | 2023.01.19 |
| [Machine Learning] scikit-learn에 대하여 (0) | 2023.01.18 |



